Real-world household tasks present significant challenges for mobile manipulation robots. An analysis of
existing robotics benchmarks reveals that successful task performance hinges on three key whole-body
control capabilities: bimanual coordination, stable and precise navigation, and extensive end-effector
reachability. Achieving these capabilities requires careful hardware design, but the resulting system
complexity further complicates visuomotor policy learning. To address these challenges, we introduce the
BEHAVIOR Robot Suite (BRS), a comprehensive framework for whole-body manipulation in diverse household
tasks.
Built on a bimanual, wheeled robot with a 4-DoF torso, BRS integrates a cost-effective whole-body
teleoperation interface for data collection and a novel algorithm for learning whole-body visuomotor
policies. We evaluate BRS on five challenging household tasks that not only emphasize the three
core capabilities but also introduce additional complexities, such as long-range navigation, interaction
with articulated and deformable objects, and manipulation in confined spaces. We believe that BRS's
integrated robotic embodiment, data collection interface, and learning framework mark a significant step
toward enabling real-world whole-body manipulation for everyday household tasks.
News
BRS powers the first BEHAVIOR
Challenge
at NeurIPS 2025, featuring 1,200+ hours of human data collected with JoyLo and WB-VIMA as a strong
baseline method.
We open-source the editable files of
JoyLo so you can
modify our design!
Core Capabilities for Daily Household Activities
What key capabilities must a robot develop to achieve daily household tasks?
To investigate this question, we analyze activities from BEHAVIOR-1K,
a human-centered robotics benchmark
encompassing 1,000 everyday household tasks, selected and defined by the general public, and
instantiated in ecological and virtual environments.
Through this analysis, we identify three essential whole-body control capabilities for successfully performing
these tasks: bimanual
coordination, stable and accurate navigation, and
extensive end-effector reachability.
Tasks such as lifting large, heavy objects require bimanual manipulation, whereas retrieving objects
throughout a house depends on stable and precise navigation. Opening a door while carrying groceries demands
the coordination of both capabilities. In addition, everyday objects are distributed across diverse locations
and heights, requiring robots to adapt their reach
accordingly.
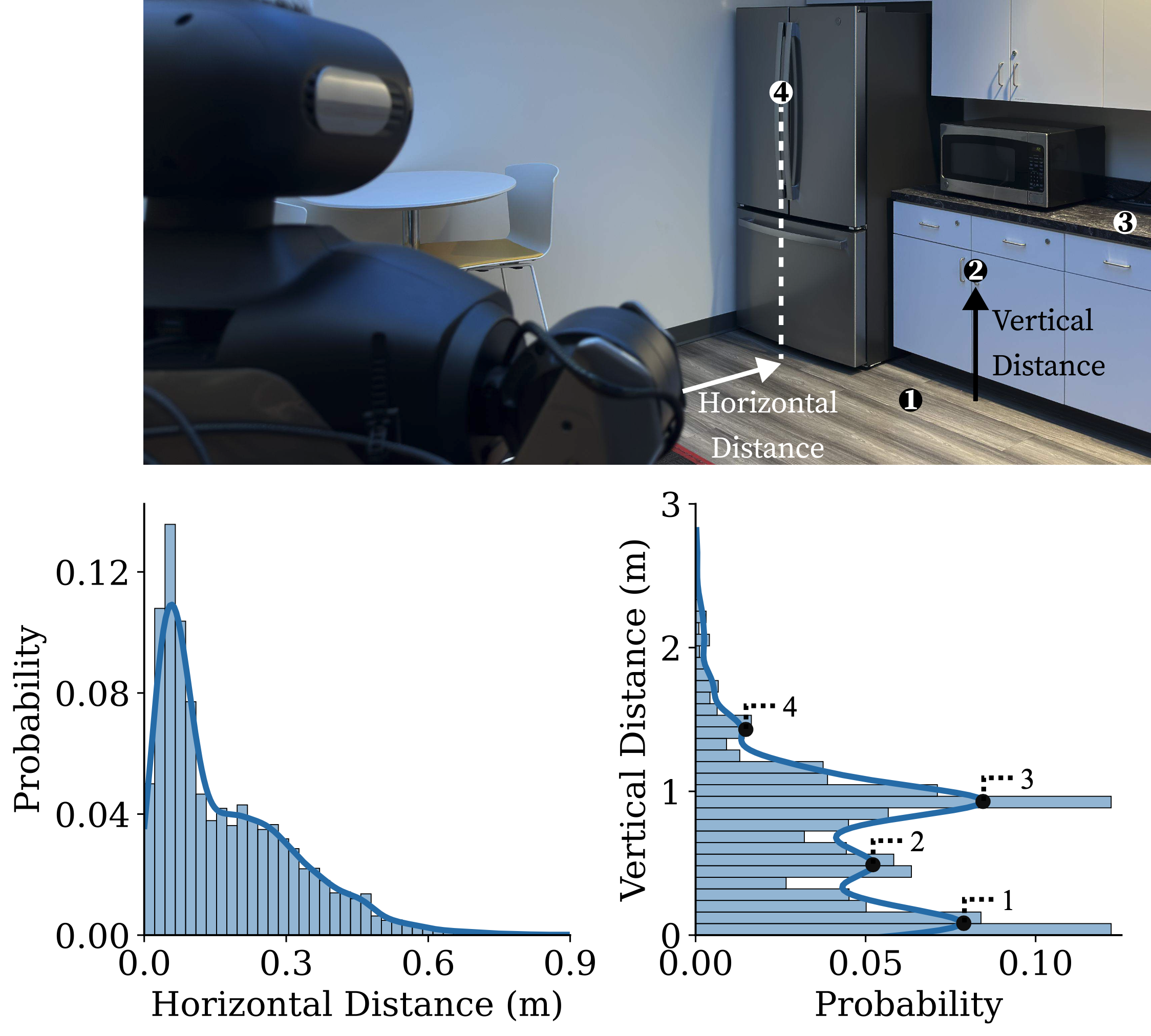
Ecological distributions of task-relevant objects involved in daily household activities.Left:
The horizontal distance distribution follows a long-tail distribution. Right: The vertical
distance distribution exhibits multiple distinct modes, located at 0.09 m, 0.49 m, 0.94 m, and 1.43
m, representing heights at which household objects are typically found. Notably, the multi-modal
distribution of vertical distances highlights the necessity of extensive end-effector reachability,
enabling a robot to interact with objects across a wide range of spatial configurations.
Carefully designed robotic hardware incorporating dual arms, a mobile base, and a flexible torso is essential to
enable whole-body manipulation. However, such designs introduce significant challenges for policy learning
methods, particularly in scaling data collection and accurately modeling coordinated whole-body actions. To
address these challenges, we introduce the BEHAVIOR Robot Suite (BRS), a comprehensive framework for
learning
whole-body manipulation to tackle diverse real-world household tasks. BRS addresses both hardware and
learning challenges through two key innovations: JoyLo and WB-VIMA.
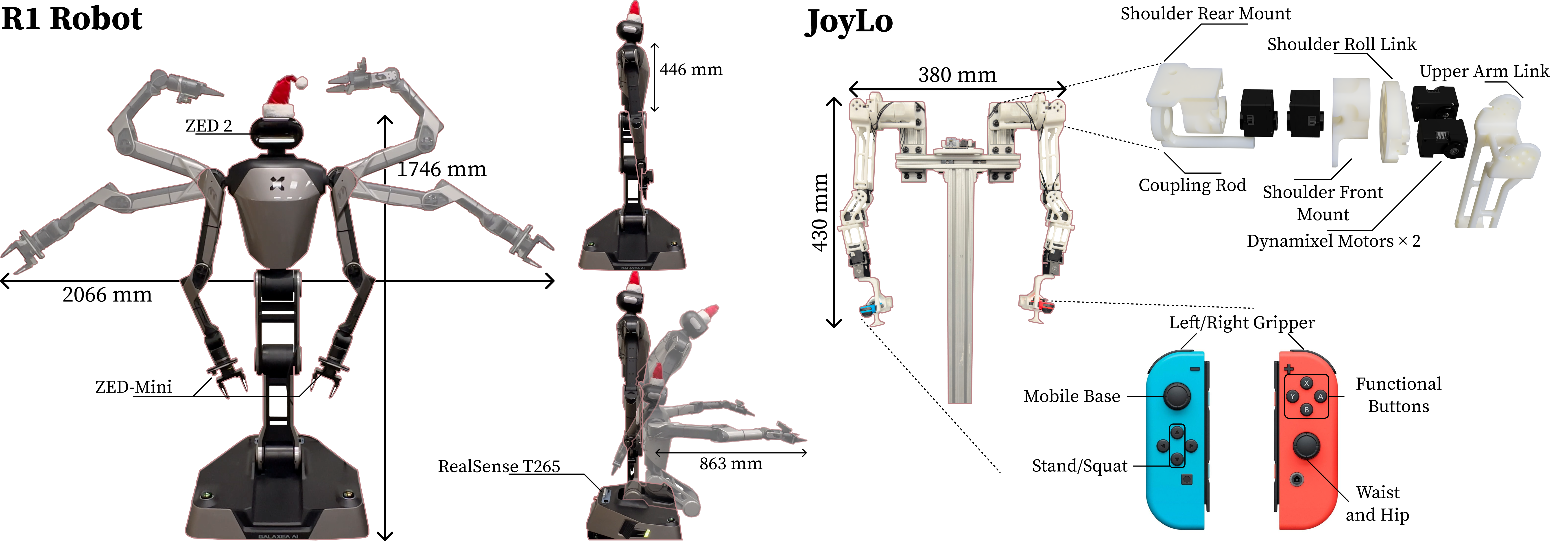
BRS hardware system overview.Left: The R1 robot used in BRS, a wheeled dual-arm
manipulator with a flexible torso. Right: JoyLo,
a low-cost, whole-body teleoperation interface designed for general applicability.
JoyLo: Joy-Con on Low-Cost
Kinematic-Twin Arms
JoyLo for whole-body teleoperation and data collection.
To enable seamless teleoperation of mobile manipulators with a high number of DoFs and facilitate data
collection for
policy learning, we introduce JoyLo—a general framework for building a cost-effective whole-body
teleoperation interface. We implement JoyLo on the R1 robot with the following design objectives:
Efficient whole-body control to coordinate complex movements;
Whole-body control example: guitar playing (4×).
Whole-body control examples: opening the refrigerator and the dishwasher (2×).
Rich user feedback for intuitive teleoperation;
Bilateral teleoperation for haptic feedback.
Ensuring high-quality demonstrations for policy learning;
User study results with 10 participants. JoyLo is the most efficient interface and
produces the highest-quality data.
Low-cost implementation to enhance accessibility;
JoyLo costs less than $500. See the Bill of Materials (BoM) here and assembly instructions here!
JoyLo bill of materials.
A real-time, user-friendly controller for seamless operation.
WB-VIMA model architecture. WB-VIMA autoregressively decodes whole-body actions within the
embodiment space and dynamically aggregates multi-modal observations using self-attention. By
leveraging the hierarchical interdependencies within the robot’s embodiment and the rich information
provided by multi-modal sensory inputs, WB-VIMA enables effective whole-body policy learning.
WB-VIMA is an imitation learning algorithm designed to model whole-body actions by leveraging the robot’s
inherent kinematic hierarchy. A key insight behind WB-VIMA is that robot joints exhibit strong
interdependencies—small movements in upstream links (e.g., the torso) can lead to large displacements in
downstream links (e.g., the end-effectors). To ensure precise coordination across all joints, WB-VIMA conditions
action predictions for downstream components on those of upstream components, resulting in more synchronized
whole-body movements. Additionally, WB-VIMA dynamically aggregates multi-modal observations using
self-attention, allowing it to learn expressive policies while mitigating overfitting to proprioceptive inputs.
Experiments
We conduct experiments to address the following research questions.
Research Questions
Q1: What household tasks are enabled by BRS, and how does WB-VIMA compare to baselines?
Q2: How different components contribute to WB-VIMA's effectiveness?
Q3: How does JoyLo compare to other interfaces in efficiency and policy learning suitability?
Q4: What other insights can be drawn about the system's capabilities?
BRS Enables Various Household Activities (Q1)
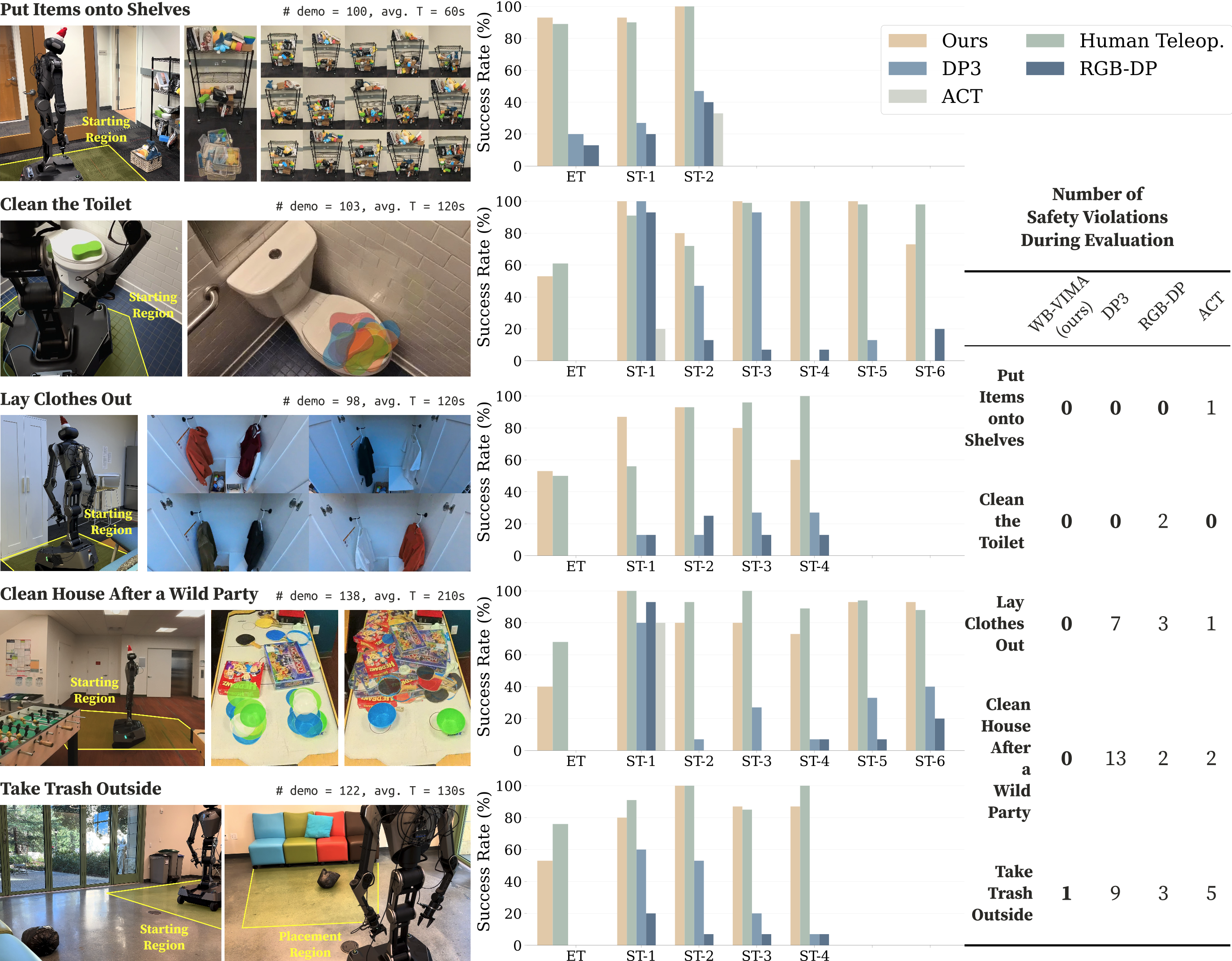
We evaluate BRS on five real-world household tasks, inspired by the everyday activities defined in BEHAVIOR-1K.
We collect 100, 103, 98, 138, and 122 trajectories using
JoyLo for these long-horizon tasks, each ranging from 60 s to 210 s. Videos below show autonomous WB-VIMA policy rollouts for each task.
Task 1: Put Items onto Shelves
In a storage room, the robot lifts a box from the ground (ST-1), moves to
a four-level shelf, and places the box on the appropriate level based on available space (ST-2). Extensive end-effector reachability is the most critical capability for this task.
Autonomous policy rollouts for the task “put items onto shelves.”
Task 2: Clean the Toilet
In a restroom, the robot picks up a sponge placed on a closed toilet (ST-1), opens the toilet cover (ST-2),
cleans the seat (ST-3), closes the cover (ST-4), and wipes it (ST-6). The
robot then moves to press the flush button (ST-6). Extensive end-effector
reachability is the most critical capability for this
task.
Autonomous policy rollouts for the task “clean the toilet.”
Task 3: Lay Clothes Out
In a bedroom, the robot moves to a wardrobe, opens it (ST-1), picks up a
jacket on a hanger (ST-2), lays the jacket on a sofa bed (ST-3), and then returns to close the wardrobe (ST-4). Bimanual coordination is the most critical capability for
this task.
Autonomous policy rollouts for the task “lay clothes out.”
Task 4: Clean House After a Wild Party
Starting in the living room, the robot navigates to a dishwasher in the kitchen (ST-1) and opens it (ST-2). It then
moves to a gaming table (ST-3) to collect bowls (ST-4). Finally, the robot returns to the dishwasher (ST-5), places the bowls inside, and closes it (ST-6). Stable and accurate navigation
is the most critical capability for this task.
Autonomous policy rollouts for the task “clean house after a wild party.”
Task 5: Take Trash Outside
The robot navigates to a trash bag in the living room, picks it up (ST-1),
carries it to a closed door (ST-2), opens the door (ST-3), moves outside, and deposits the trash bag into a trash bin (ST-4). Stable and accurate navigation
is the most critical capability for this task.
Autonomous policy rollouts for the task “take trash outside.”
For baseline comparison, we include DP3, RGB-DP,
and ACT. We additionally report human teleoperation success and policy
safety violations, defined as robot collisions or motor power losses due to excessive force. Each task is
segmented into multiple sub-tasks (“ST”). During evaluation, if a
sub-task fails, we reset to the start of the next sub-task and continue evaluation. We also report
the end-to-end success rates for entire tasks (“ET”). Each policy is
evaluated 15 times with randomized robot starting position, target object placement, target object instance,
and distractors. Each task covers at least two types of randomization.
Evaluation results for five household tasks.Left: Initial randomization.
Middle: Success rates over 15 runs (“ET” = entire task, “ST” = sub-task). Right:
Number of safety violations.
As shown in the figure above, WB-VIMA consistently outperforms the baseline methods across all tasks. For
end-to-end task success, WB-VIMA achieves 13× and 21× higher success rates than DP3 and RGB-DP, respectively.
For average sub-task performance, it outperforms them by 1.6× and 3.4×. ACT fails to complete any full tasks and
rarely succeeds in sub-tasks.
These baselines struggle because they directly predict flattened 21-DoF actions, ignoring hierarchical
dependencies within the action space. As a result, modeling errors in mobile base or torso predictions cannot be
corrected by arm actions, leading to amplified end-effector drift, pushing the robot into out-of-distribution
states, and eventually resulting in task failures. Uncoordinated whole-body actions also increase safety
violations, such as DP3 colliding with tables, RGB-DP losing arm power from excessive force, and ACT hitting
doorframes during trash disposal. We show several baseline methods' failure cases in the videos below.
Failure cases of baseline methods.
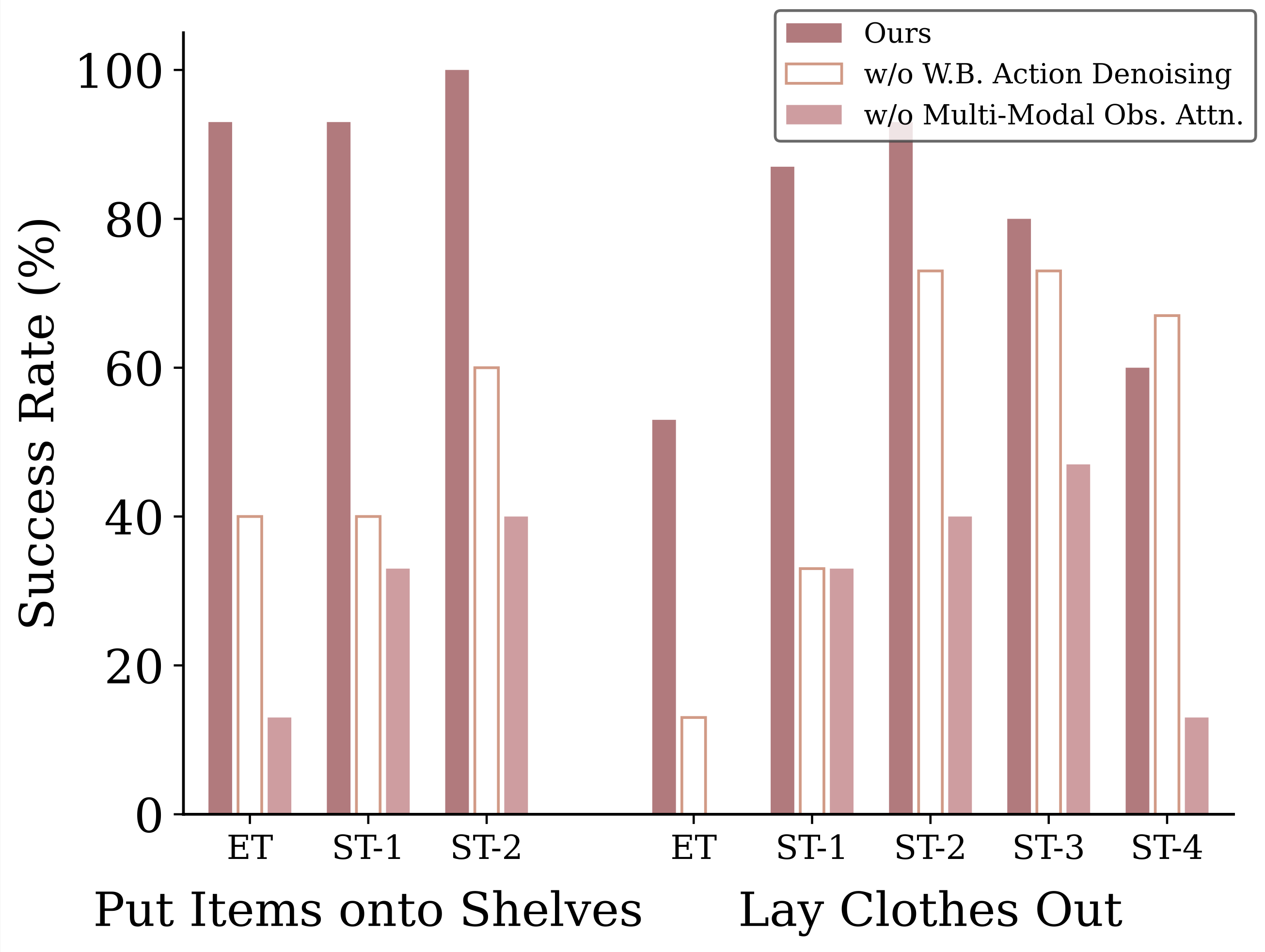
Effects of WB-VIMA’s Components on Task Performance (Q2)
We evaluate two WB-VIMA variants: one without autoregressive whole-body action decoding
and one without multi-modal observation attention.
Real-world ablation results for “put items onto shelves” and “lay clothes out.”
As shown in the figure above, removing either significantly degrades performance. Tasks like “put items onto
shelves” and “open wardrobe” (ST-1) in “lay clothes out” critically depend on coordinated whole-body actions;
removing autoregressive action decoding leads to up to a 53% performance drop. Removing multi-modal attention
reduces performance across all tasks, causing the model to ignore visual inputs and overfit to proprioception.
Four collisions are also observed due to poor visual awareness.
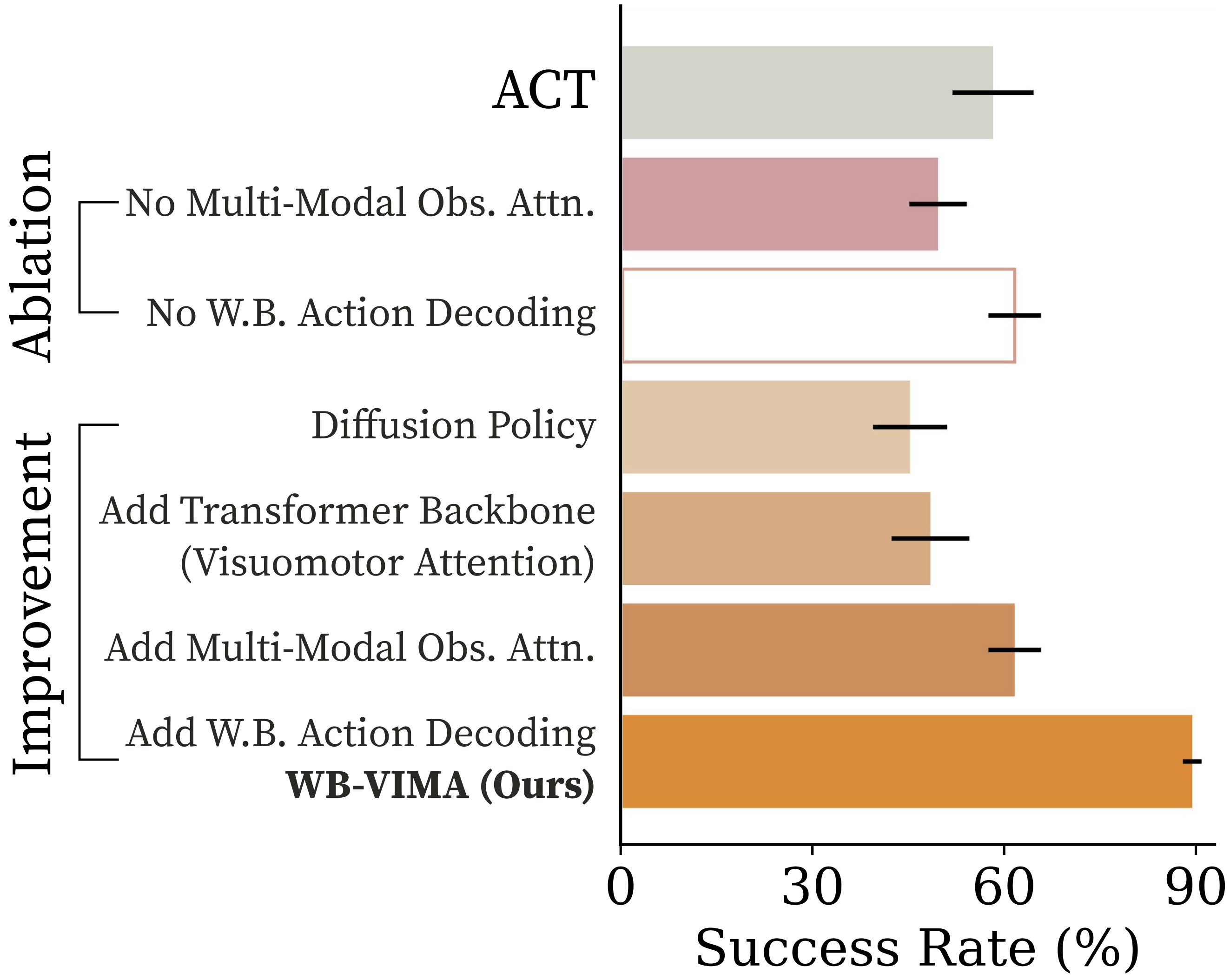
The same conclusions hold in a simulated table wiping task as shown below. Furthermore, starting
from a vanilla diffusion policy, we provide a roadmap improving the model success by progressively adding
components: multi-modal observation attention improves by 27% and surpasses ACT; adding autoregressive
whole-body action decoding further boosts success by 45%, culminating in WB-VIMA’s strong final performance.
Simulation ablation results for “wiping table.” The robot must wipe toward the goal using
whole-body motions while maintaining continuous hand contact. Results are averaged over
five runs with 100
rollouts each; error bars indicate standard deviation.
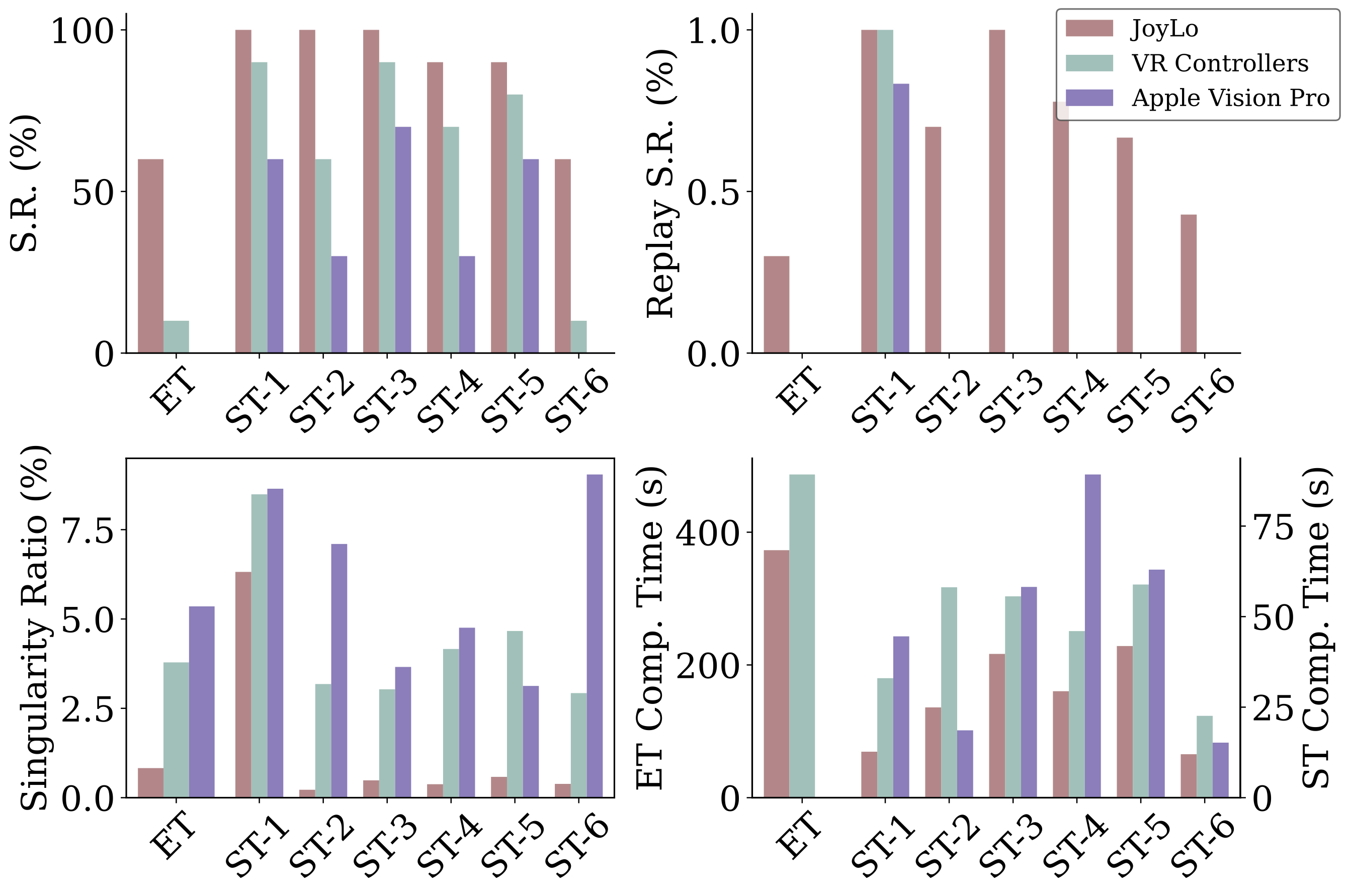
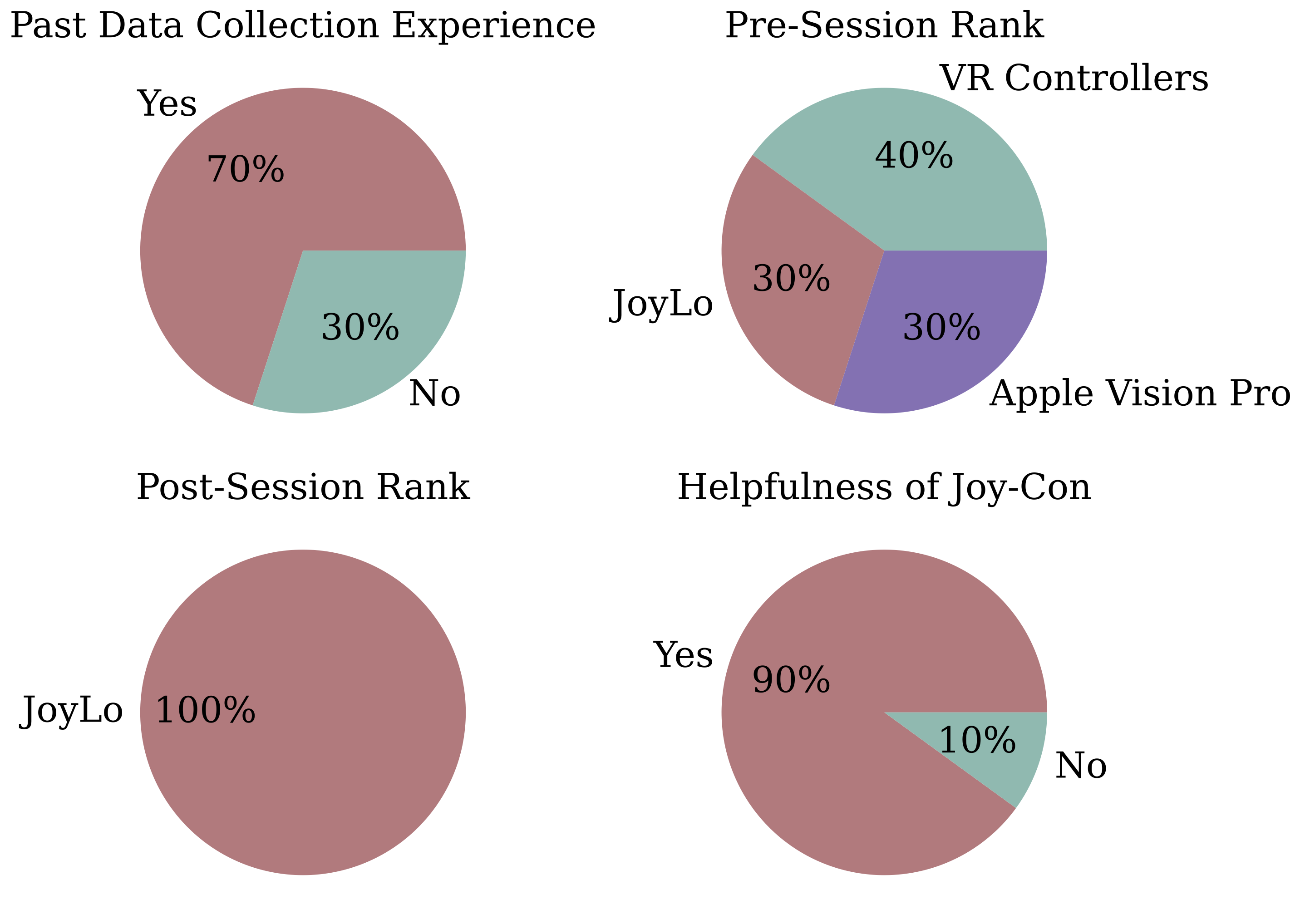
JoyLo is an efficient, user-friendly interface that provides high-quality data for policy learning (Q3)
We conducted a user study with 10 participants to evaluate JoyLo against two IK-based interfaces: VR controllers and Apple Vision Pro.
The study was performed in the OmniGibson simulator on the “clean house after a wild party” task.
User study. From left to right: JoyLo, VR controllers, and Apple Vision Pro.
An example user study trajectory.
We measured success rate (↑, higher is better), completion time (↓, lower is better), replay
success rate (↑), and singularity ratio (↓) across entire tasks (“ET”) and sub-tasks (“ST”).
Replay success measures the open-loop execution of collected robot trajectories, where higher values indicate
higher-quality, verified data that allows imitation learning policies to better model
trajectories.
User study results, participant demographics, and questionnaire results. “S.R.” is success
rate. “ET Comp. Time” and “ST Comp. Time” refer to
entire and sub-task completion times.
As shown in the figure above, JoyLo achieves the highest success rate and fastest completion time across all
interfaces. It delivers a 5× higher task success rate and 23% shorter median completion time than VR
controllers, while no participants completed the entire task with Apple Vision Pro. JoyLo particularly
excels at articulated object manipulation (e.g., 67% higher success in “open dishwasher” (ST-2) than VR
controllers), enabling users to generate smooth and accurate actions, which is consistent with findings that
leader-follower arm control improves fine-grained manipulation. It also significantly reduces sub-task times
(e.g., 71% faster navigation and 67% faster bowl picking) compared to Apple Vision Pro, whose reliance on head
movement for mobile base control leads to poor coordination and tracking. Moreover, JoyLo provides the
highest data quality, achieving the lowest singularity ratio (78% and 85% lower than VR controllers and Apple
Vision Pro, respectively) and consistently replaying successful trajectories.
In user surveys, all participants rated JoyLo the most user-friendly. Although 70% of participants initially
believed IK-based interfaces would be more intuitive, after the study they unanimously preferred JoyLo. This
shift underscores a key distinction between tabletop data collection and mobile whole-body manipulation: while
IK-based methods may suffice for static setups, they struggle to effectively control the mobile base and torso,
making high-quality data collection much harder in mobile manipulation settings.
Coordinated torso and mobile base movements enhance maneuverability beyond stationary arms (Q4)
As shown in figures and videos below, coordinated whole-body movements are critical for tasks involving heavy
articulated object interactions, such as “open the door” (ST-3) in “take trash outside” and “open the
dishwasher” (ST-2) in “clean house after a wild party.”
To open a door, the robot bends its hip forward while advancing the base to generate enough inertia; to open a
dishwasher, it moves the base backward, using its whole body to pull the door open smoothly.
Without hip or base movement, both objects remain closed and the arm joint effort would surge, generating
excessive force that is potentially harmful to the hardware.
Coordinated torso and mobile base movements enhance maneuverability.Left: With hip or
mobile base. Right: Without hip or mobile base. WB-VIMA policies use the hip and mobile base
to open a door and dishwasher; if the torso or mobile base is locked, opening fails and arm joint
effort surges, risking hardware damage.
Additionally, we observe that the robot learns to recover from failures. As shown in videos below, when the
robot was opening the wardrobe door, one door was not fully opened. The robot then moves
backward a bit, attempts to open the door again, and successfully opens it.
Similarly, when robot fails to close the toilet cover due to the limited arm reach, it tilts its torso forward,
bringing its
arms closer to the toilet. The robot then retries, grasps the toilet cover successfully, and closes the lid
smoothly.
Emergent behaviors of failure recovery.
Failure Cases
We show several failure cases of learned WB-VIMA policies. They include 1) failure to fully open the dishwasher
despite that the robot has grasped the handle; 2) failure to press the flush button; 3) failure to pick up the
trash bag from the floor; 4) failure to lift the box on the floor; and 5) failure to close the wardrobe door.
Several failure cases of learned WB-VIMA policies.
Conclusion
This paper presents BRS, a holistic framework for learning whole-body manipulation to tackle diverse
real-world household tasks.
We identify three core capabilities essential for household activities: bimanual coordination, stable
navigation, and extensive end-effector reachability.
Achieving these with learning-based methods requires overcoming challenges in both data and modeling.
BRS addresses them through two innovations: 1) JoyLo, a cost-effective whole-body interface for
efficient data collection, and 2) WB-VIMA, a novel algorithm that leverages embodiment hierarchy and models
interdependent whole-body actions.
The BRS system demonstrates strong performance across real-world household tasks with unmodified objects in
natural, unstructured environments, marking a step toward greater autonomy and reliability in household
robotics.
Acknowledgement
We thank Chengshu (Eric) Li, Wenlong Huang, Mengdi Xu, Ajay Mandlekar, Haoyu Xiong, Haochen Shi, Jingyun Yang,
Toru Lin, Jim Fan, and the SVL PAIR group for their invaluable technical discussions. We also thank Tianwei Li
and the development team at Galaxea.ai for timely hardware support, Yingke Wang for helping with the figures,
Wensi Ai and Yihe Tang for helping with the video filming, Helen Roman for processing hardware purchase, Frank
Yang, Yihe Tang, Yushan Sun, Chengshu (Eric) Li, Zhenyu Zhang, Haoyu Xiong for participating in user studies,
and the Stanford Gates Building community for their patience and support during real-robot experiments. This
work is in part supported by the Stanford Institute for Human-Centered AI (HAI), the Schmidt Futures Senior
Fellows grant, NSF CCRI #2120095, ONR MURI N00014-21-1-2801, ONR MURI N00014-22-1-2740, and ONR MURI
N00014-24-1-2748.
BibTeX
@inproceedings{jiang2025brs,
title={{BEHAVIOR} Robot Suite: Streamlining Real-World Whole-Body Manipulation for Everyday Household
Activities},
author={Yunfan Jiang and Ruohan Zhang and Josiah Wong and Chen Wang and Yanjie Ze and Hang Yin and Cem Gokmen
and Shuran Song and Jiajun Wu and Li Fei-Fei},
booktitle={9th Annual Conference on Robot Learning},
year={2025},
url={https://openreview.net/forum?id=v2KevjWScT}
}